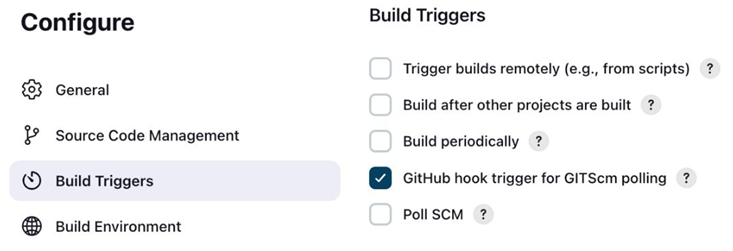
The Blog App and its deployment configuration – Continuous Deployment/ Delivery with Argo CD
Since we discussed the Blog App in the last chapter, let’s look at the services and their interactions again:
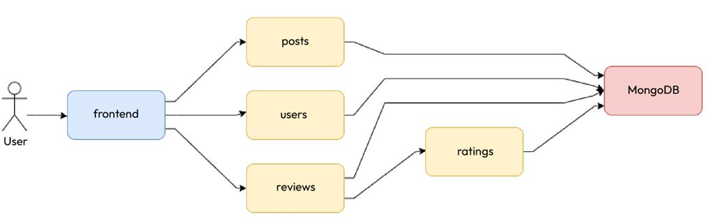
Figure 12.5 – The Blog App and its services and interactions
So far, we’ve created CI pipelines for building, testing, and pushing our Blog App microservice containers. These microservices need to run somewhere. So, we need an environment for this. We will deploy the application in a GKE cluster; for that, we will need a Kubernetes YAML manifest. We built the container for the posts microservice as an example in the previous chapter, and I also left building the rest of the services as an exercise for you. Assuming you’ve built them, we will need the following resources for the application to run seamlessly:
- MongoDB: We will deploy an auth-enabled MongoDB database with root credentials. The credentials will be injected via environment variables sourced from a Kubernetes Secret resource. We also need to persist our database data, so for that, we need a PersistentVolume mounted to the container, which we will provision dynamically using a PersistentVolumeClaim. As the container is stateful, we will use a StatefulSet to manage it and, therefore, a headless Service to expose the database.
- Posts, reviews, ratings, and users: The posts, reviews, ratings, and users microservices will interact with MongoDB through the root credentials injected via environment variables sourced from the same Secret as MongoDB. We will deploy them using their respective Deployment resources and expose all of them via individual ClusterIP Services.
- Frontend: The frontend microservice does not need to interact with MongoDB, so there will be no interaction with the Secret resource. We will also deploy this service using a Deployment resource. As we want to expose the service on the internet, we will create a LoadBalancer Service for it.
We can summarize these aspects with the following diagram:
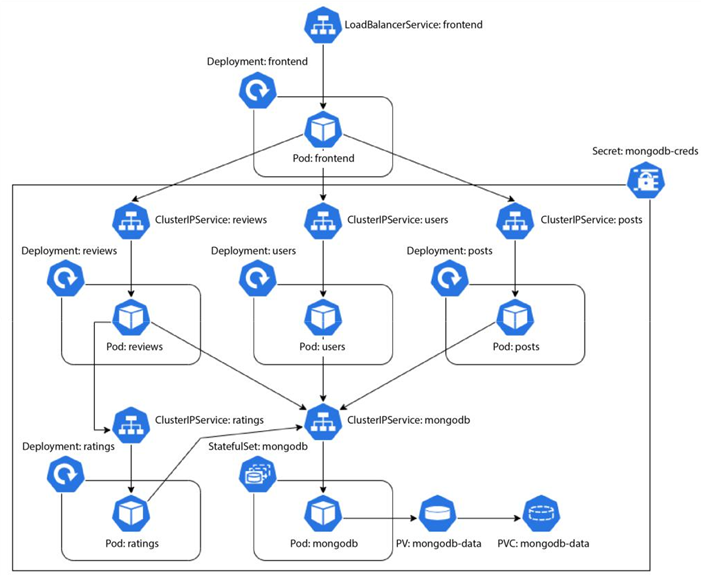
Figure 12.6 – The Blog App – Kubernetes resources and interactions
Now, as we’re following the GitOps model, we need to store the manifests of all the resources on Git. However, since Kubernetes Secrets are not inherently secure, we cannot store their manifests directly on Git. Instead, we will use another resource called SealedSecrets to manage this securely.
In Chapter 2, Source Code Management with Git and GitOps, we discussed application and environment repositories forming the fundamental building blocks of GitOps-based CI and CD, respectively. In the previous chapter, we created an application repository on GitHub and used GitHub Actions (and Jenkins) to build, test, and push our application container to Docker Hub. As CD focuses on the Ops part of DevOps, we will need an Environment repository to implement it, so let’s go ahead and create our Environment repository in the next section.