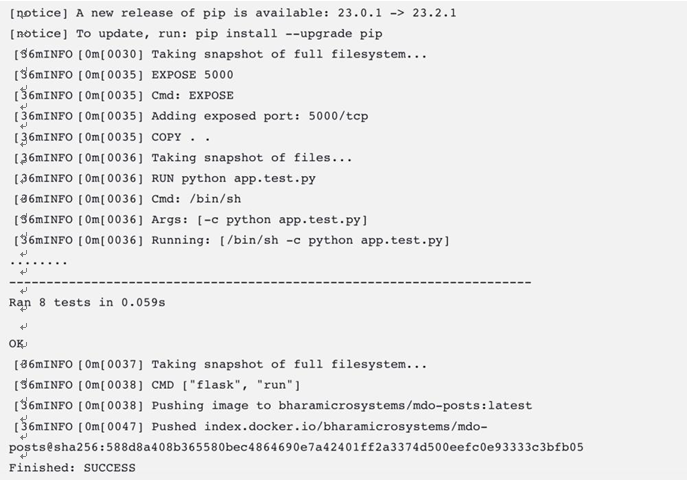
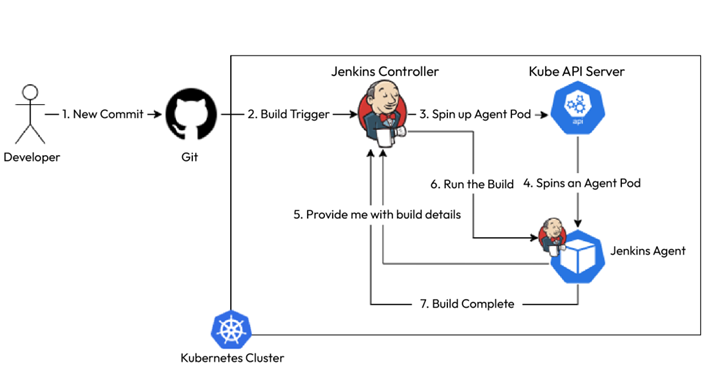
CD models and tools – Continuous Deployment/ Delivery with Argo CD
A typical CI/CD workflow looks as described in the following figure and the subsequent steps:
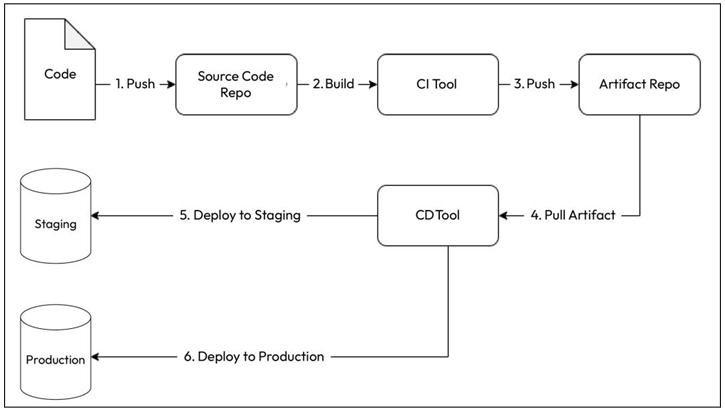
Figure 12.1 – CI/CD workflow
- Your developers write code and push it to a code repository (typically a Git repository).
- Your CI tool builds the code, runs a series of tests, and pushes the tested build to an artifact repository. Your CD tool then picks up the artifact and deploys it to your test and staging environments. Based on whether you want to do continuous deployment or delivery, it automatically deploys the artifact to the production environment.
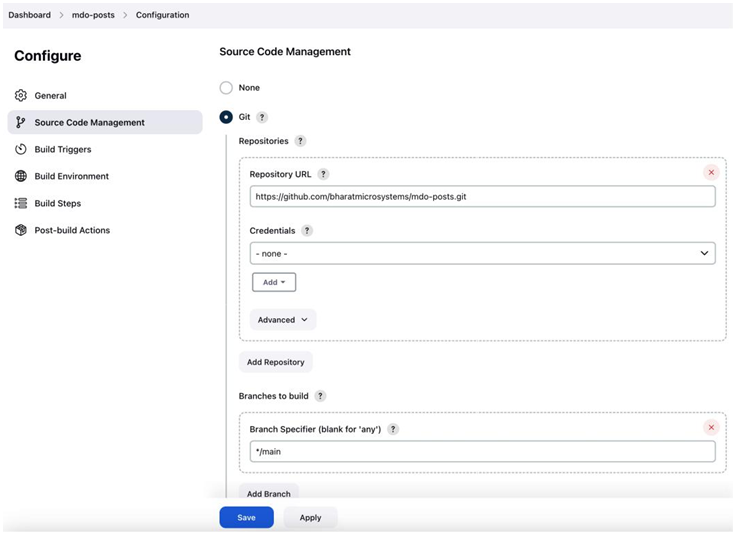
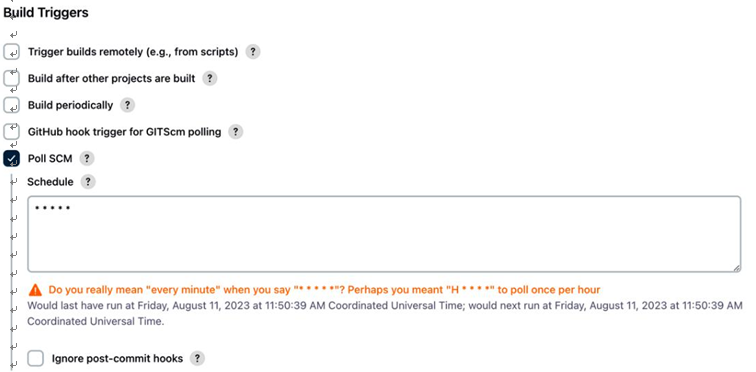
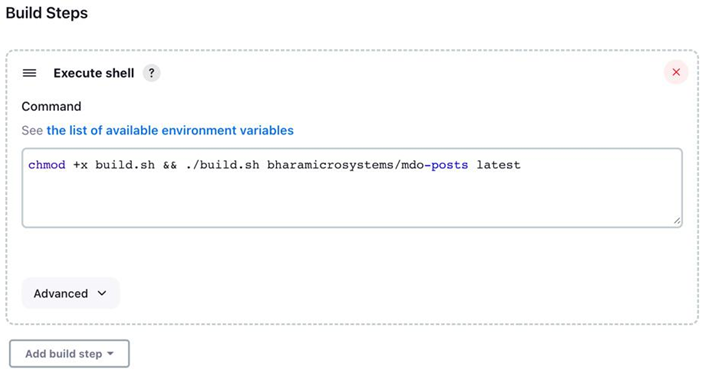
Well, what do you choose for a delivery tool? Let’s look at the example we covered in Chapter 11, Continuous Integration. We picked up the posts microservice app and used a CI tool such as GitHubActions/Jenkins that uses Docker to create a container out of it and push it to our Docker Hub container registry. Well, we could have used the same tool for deploying to our environment.
For example, if we wanted to deploy to Kubernetes, it would have been a simple YAML update and kubectl apply. We could easily do this with any of those tools, but we chose not to do it. Why? The answer is simple – CI tools are meant for CI, and if you want to use them for anything else, you’ll get stuck at a certain point. That does not mean that you cannot use these tools for CD. It will only suit a few use cases based on the deployment model you follow.
Several deployment models exist based on your application, technology stack, customers, risk appetite, and cost consciousness. Let’s look at some of the popular deployment models that are used within the industry.
Simple deployment model
The simple deployment model is one of the most straightforward of all: you deploy the required version of your application after removing the old one. It completely replaces the previous version, and rolling back involves redeploying the older version after removing the deployed one:
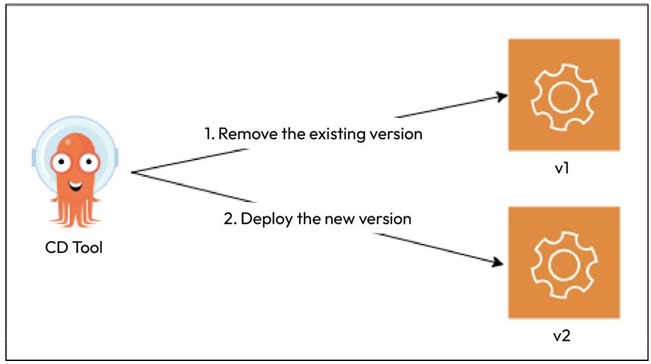
Figure 12.2 – Simple deployment model
As it is a simple way of deploying things, you can manage this using a CI tool such as Jenkins or GitHub Actions. However, the simple deployment model is not the most desired deployment methodbecause of some inherent risks. This kind of change is disruptive andtypically needs downtime. This means your service would remain unavailable to your customers for the upgrade period. It might be OK for organizations that do not have users 24/7, but disruptions eat into the service-level objectives (SLOs) and service-level agreements (SLAs) of global organizations. Even if there isn’t one, they hamper customer experience and the organization’s reputation.
Therefore, to manage such kinds of situations, we have some complex deployment models.