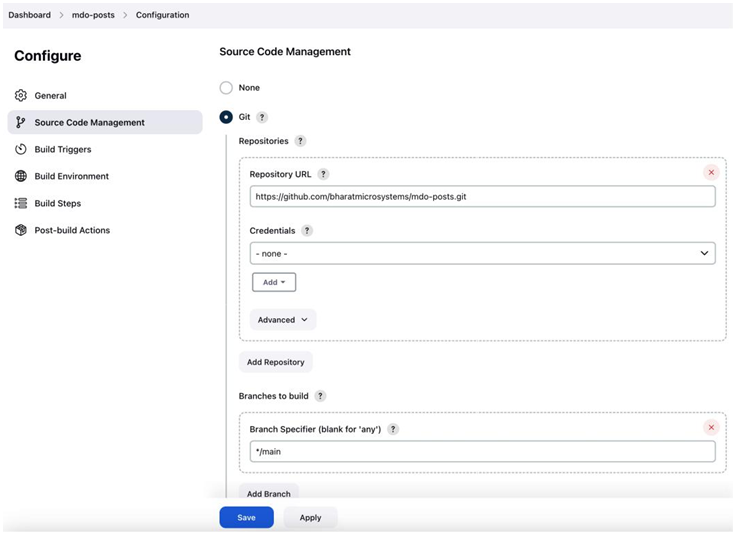
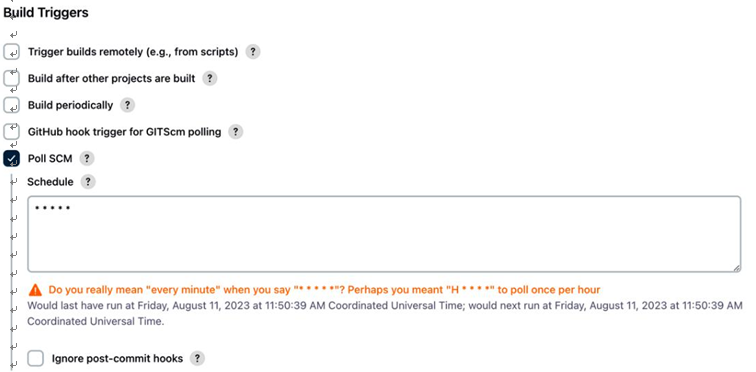
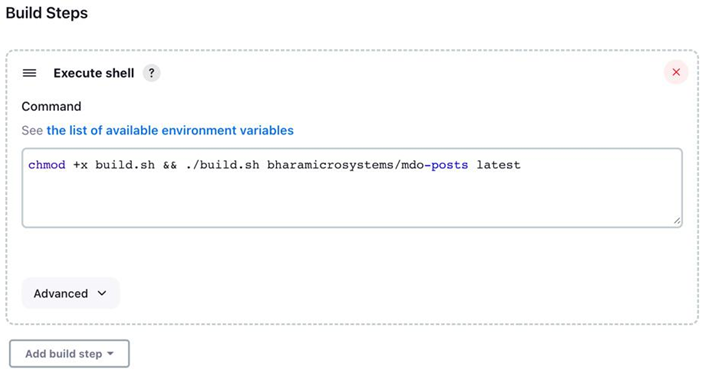
The importance of CD and automation – Continuous Deployment/ Delivery with Argo CD-1
CD forms the Ops part of your DevOps toolchain. So, while your developers are continuously building and pushing code and your CI pipeline is building, testing, and publishing the builds to your artifact repository, the Ops team will deploy the build to the test and staging environments. The QA team is the gatekeeper that will ensure that the code meets a certain quality, and only then will the Ops team deploy the code to production.
Now, for organizations implementing only the CI part, the rest of the activities are manual. For example, operators will pull the artifacts and run commands to do the deployments manually. Therefore, your deployment’s velocity will depend on the availability of your Ops team to do it. As the deployments are manual, the process is error-prone, and human beings tend to make mistakes in repeatable jobs.
One of the essential principles of modern DevOps is to avoid toil. Toil is nothing but repeatable jobs that developers and operators do day in and day out, and all of that toil can be removed by automation. This will help your team focus on the more important things at hand.
With continuous delivery, standard tooling can deploy code to higher environments based on certain gate conditions. CD pipelines will trigger when a tested build arrives at the artifact repository or, in the case of GitOps, if any changes are detected in the Environment repository. The pipeline then decides, based on a set configuration, where and how to deploy the code. It also establishes whether manual checks are required, such as raising a change ticket and checking whether it’s approved.
While continuous deployment and delivery are often confused with being the same thing, there is a slight difference between them. Continuous delivery enables your team to deliver tested code in your environment based on a human trigger. So, while you don’t have to do anything more than click a button to do a deployment to production, it would still be initiated by someone at a convenient time (a maintenance window). Continuous deployments go a step further when they integrate with the CI process and will start the deployment process as soon as a new tested build is available for them to consume. There is no need for manual intervention, and continuous deployment will only stop in case of a failed test.
The monitoring tool forms the next part of the DevOps toolchain. The Ops team can learn from managing their production environment and provide developers with feedback regarding what they need to do better. That feedback ends up in the development backlog, and they can deliver it as features in future releases. That completes the cycle, and now you have your team churning out a technology product continuously.