Introduction to the sample microservices-based blogging application – Blog App – Continuous Integration with GitHub Actions and Jenkins
Blog App is a sample modern microservices- based blogging web application that allows users to create, manage, and interact with blog posts. It caters to both authors and readers. Users can sign up to this platform using their email addresses and start writing blog posts. Readers can publicly view all blog posts created by several authors, and logged-in users can also provide reviews and ratings.
The application is written in a popular Python-based web framework called Flask and uses MongoDB as the database. The application is split into several microservices for user, post, review, and rating management. There is a separate frontend microservice that allows for user interaction. Let’s look at each microservice:
- User Management: The User Management microservice provides endpoints to create a user account, update the profile (name and password), and delete a user account.
- Posts Management: The Posts Management microservice provides endpoints to create, list, get, update, and delete posts.
- Reviews Management: The Reviews Management microservice allows users to add reviews on posts and update and delete them. Internally, it interacts with the Ratings Management microservice to manage the ratings provided, along with the reviews.
- Ratings Management: The Ratings Management microservice manages ratings for posts associated with a particular review. This microservice is called from the Reviews Management microservice internally and is not exposed to the Frontend microservice.
- Frontend: The Frontend microservice is a Python Flask user interface application built using Bootstrap, which provides users with a rich and interactive user interface. It allows users to sign up, log in, view, and navigate between posts, edit their posts, add and update reviews, and manage their profiles. The microservice interacts with the backend microservices seamlessly using HTTP requests.
The users, posts, reviews, and ratings microservices interact with MongoDB as the database.
The following service diagram shows the interactions graphically:
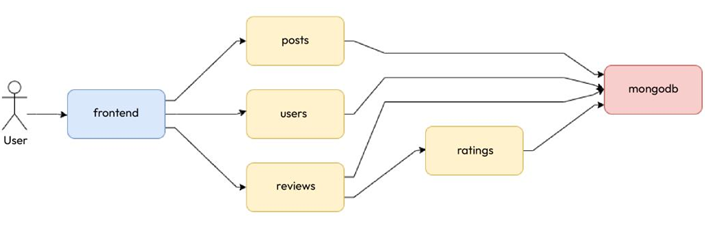
Figure 11.1 – Blog App services and interactions
As we can see, the individual microservices are fairly decoupled from each other and, therefore, can independently scale. It is also robust because the other parts of the application will work if a particular microservice is not working. The individual microservices can be independently developed and deployed as separate components, adding to the application’s flexibility and maintainability. This application is an excellent example of leveraging microservices to build a modern, feature-rich web application.
Now, let’s implement CI for this application. To implement CI, we will need a CI tool. We’ll look at some of the popular tools and the options you have in the next section.